📚 分类
redis
🕵🏽♀️ 问题描述
哨兵模式脑裂情况是如何产生的,应该如何避免?
👨🏫 问题讲解
❒ 集群脑裂是由于主节点和从节点和sentinel处于不同的网络分区,使得sentinel没有能够心跳感知到主节点,所以通过选举的方式提升了一个从节点为主,这样就存在了两个master,就像大脑分裂了一样,这样会导致客户端还在老的主节点那里写入数据,新节点无法同步数据,当网络恢复后,sentinel会将老的主节点降为从节点,这时再从新master同步数据,就会导致数据丢失。 解决:我们可以修改redis的配置,就可以避免大量的数据丢失。 ❒ redis中有两个配置参数: # 与主节点通信的从节点数量必须大于等于该值主节点,否则主节点拒绝写入 # 表示最少的salve节点为1个 min-slaves-to-write 1 # 主节点与从节点通信的ACK消息延迟必须小于该值,否则主节点拒绝写入 # 表示数据复制和同步的延迟不能超过5秒 min-slaves-max-lag 5 ✔ 这两个配置项必须同时满足,不然主节点拒绝写入。在假故障期间不满足min-slaves-to-write和min-slaves-max-lag的要求,那么主节点就会被禁止写入,脑裂造成的数据丢失情况自然也就解决了。
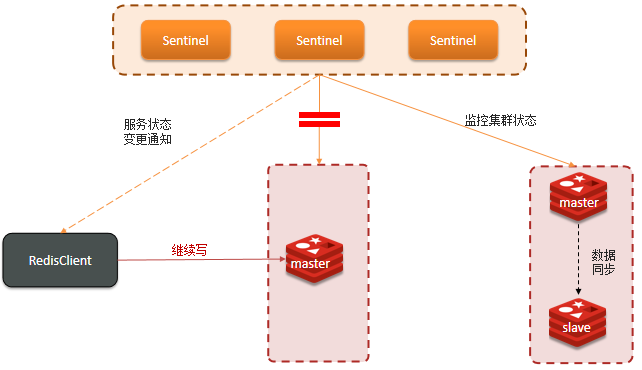
🏳️🌈 问题总结
✔ 可以设置最少的从节点数量以及缩短主从数据同步的延迟时间,达不到要求就拒绝请求。
📖 问题信息
📈 浏览次数:16 |
📅 更新时间:2025-12-03 19:19:29
📦 创建信息
🏷️ ID:16 |
📅 创建时间:2024-10-08 15:42:05